Унших хугацаа: 25 минут
Монголын нэг өдөр нэг иймэрхүү маягтай. Дээшээ харлаа гадаадад тэглээ ингэлээ гэх том том яригчид, баруун тийшээ харлаа хаа газрын нэг танил гадны нэг технологийн талаар лекц хийнэ гэнэ, зүүн тийшээ харлаа өөр нэг нүдэнд харагддаг байсан бачка гадаадад ингэж байгаа учраас бид ингэх хэрэгтэй гэх мэт төрөл бүрийн аман бардагчид (social influencer), доошоо харлаа насаар хэд дүү бас гадны тэр тийм юм ингэдэг тэгдэг гэж цуурч байх нь ч харагдана. Жишээлбэл тэр нэг роботикийн судлаачдын ичвэр болсон Софи робот байна. Судлаачдын дунд бол онигоо гэж яригдаж байгаа ч тэрний талаарх мэдээлэл олонд бол шал эсрэгээрээ. Чухам яагаад гэдгийг амаараа бардагчдаас л асуусан нь дээр биз.
Оооокккэээй, ямартай ч ямарваа чимээний цуурай болж гадны сайтуудын хов жив дамжуулж явах ч яахав тийм байж. Хүмүүс өөрийнхөө амьдралынхаа цагийг юунд дэмий үрнэ надад хамаагүй л дээ. Надад бол чухам яагаад, яаж, хэрхэн тэр мундаг технологиуд хөгжөөд байгаа талаар тэдгээрийн үндэс суурь нь юунд байв гэдэг л сонин. Яаж тийм технологи хөгжүүлэв, ямар байдлаас хөгжүүлэв, юуны тулд хөгжүүлэв, ямар үр дүнд хүрэхийг зорьсон, ямарваа боломжит алдаа дутагдал бий эсэх гэх мэт талаас нь харж боддог гэх юм уу. Түүнээс за арасо арасо дэлхийг хиймэл оюун ухаан эзлээд Монгол улс тэр бүхнээс хоцроод мацагаа барина хүмүүсийн үгээр бол.
Тэгэхээр миний бие одоо үед шинжлэх ухаанд өргөн хэрэглэгдэж буй арга барилаас өөрийн үзэл бодлыг нийтлэл болгон бичдэг юм уу гэв бодов. Лаг мундаг эрдэмтэн лугаа жанживлангунсансэрэнжүмпүүлээгийн дүрээр биш зүгээр нэг жирийн тооцоолон бодох ухааны шинжээчийн (computer scientist) нүдээр харагдах зүйлсийн талаарх шүү. Чухам юуны талаарх вэ гэвэл гурван зүйл:
- Машин сургалт (Machine learning)
- Загварчилсан тооцоолол (Simulation modelling)
- Алгоритм (Advanced Algorithm)
Эдгээрт ашиглагддаг арга барил бол одоо үед шинжлэх ухааны бүхий л салбарт ашиглагддаг. Хими, биологи, физик, програмчлалаас гадна нийгмийн ухааны судалгаанд ч хэрэглэгддэг. Түүнээс гадна өргөн хэрэглээнд ашиглаанд ороод буй технологиуд бидний мэдэд аппууд ч гэсэн дээрх аргачлал дээр үндэслэгдсэн байх нь олонтаа. Чухам юунд яаж хэрэглэгдэж вэ гэдгийг бол тэгээд аль нэг гадны технологийн талаарх сайтаас харчих.
Дээрх гурваас гадна нэг том шинжлэх ухааны арга барил хөгжиж буй нь Bio-Inspired computation. Биологи, хими гэдэг үг орсон болгоноос зугтдаг учраас энийг би орхиж байгаа. Анхааруулж хэлэхэд тэр чиглэлийг 21-р зуунд гол нээлтүүд хийгдэх ухаан гэж ярьдаг шүү. Мэдээж тэгээд цэвэр онолоос ургаж гарч ирсэн хандлага эдгээр дээр нэмэгдэнэ. Харин тэрийг бол уг шинжлэх ухааны мэргэжлийн судлаачдын л хэлэх зүйлс хойно миний дурьдаад байх зүйл биш. Яахав ганц хоёр хүнд ч болов хэрэг болоод тэдний тархинд суурьтай сэтгэлгээний дөл асаах ч юм уу ирээдүйд ямар мэргэжилтэй болох вэ гэж гайхдаг дүү нарт хэрэг болж магад.
Machine Learning
За энэ чинь юу билээ? Whoa machine learning, deep learning, artificial intelligence. Cool. Deep learning чинь нөгөө бүгдийг хийж чаддаг мундаг технологи, нөгөө хэд нь бол яахав нэг тийм лаг мундаг биш бла бла бла.
Ok, тэр ч арай биш юм аа. Юуны өмнө хиймэл оюун ухааны талаар болон энэ шинжлэх ухааны хөгжлийн талаар бичсэн миний нийтлэлийг уншиж үз. Энэ талаар хэн ч дуугардаггүй байхад хэдэн жилийн өмнө бичигдсэн тэр нийтлэлд хиймэл оюун ухааныг хөгжиж эхэлсэн үеээс эхлээд чухам яаж, яагаад гэдэг талаас нь барьж дурьдсан буй. Мэдээж их түүхтэй шинжлэх ухаан тул нэг нийтлэлд бүгд багтана ч гэж юу байхав, тэр нийтлэлд Expert system, knowledge engineering-н үе хүртэл бичигдээд machine learning хөгжиж эхлэхээс өмнөх үе хүртэл бичигдсэн. Харин одоо энд тэрнээс хойших үе буюу machine learning гэж юу болохыг бичье.
За knowledge engineering арга барилд юу дутагдаж байв? Уг нь ямар нэг мэргэжилтэний мэдлэгийг компьютерт хуулж аваад тэрнийхээ дагуу програм бүтээх бол байж болох л бодол. Тэрний дагуу ч тийм арга барил хөгжөөд зарим салбарт амжилт олж болоод л байв. Гэхдээ юунд тэр аргачлал зохимж муутай байв? Уг аргачлалын дутагдал юунд байв? За бодоод үз. Нэг нөхөр байв аа. Лагаас лаг мундаг нь хэтийдсэн нь дэндүү гэж аргагүй. Яг манай мундагууд шиг бүүр байгалиасаа гэдэг шиг л. Тэр нөхрийн мэргэжлийн мэдлэгийг яг таг хуулах програм хийх болж. Хамгийн эхэнд тэр нөхрийн толгой доторх бүх зүйлийг хуулж авах болно. Яаж? Аманд нь алчуур чихэж байгаад ус руу толгойг нь дүрж байцааж уу? Эсвэл бүх зүйлийг нь цаасанд бичүүлэх үү? За ямар нэг байдлаар програмдаа тэр хүний мэргэжлийн талаарх бүх зүйлсийг хялбар маягтай тийм үгүй гэж хариулахаар орууллаа гэж бодьё. Тэгвэл тэр хүн хэдийн хугацаанд уг компьютерт суугаад тэр маягтыг бөглөх дуусгах вэ? Өөрөө бол хэдэн арван жил сурсан зүйл, өөрөөс нь өмнөх хүмүүс хэдэн зуун жил хөгжүүлсэн шинжлэх ухааныг хэр хугацаанд компьютерт хуулж чадах бол? За ямар нэг байдлаар хуулаад орууллаа гэхэд нөгөө програм маань зөвхөн тэр зүйлд, зөвхөн тэр мэргэжилтэн шиг, зөвхөн тодорхой тооцож боловсруулсан асуудал шийдэх л болно. Яг таг асуудал шийднэ гэх ч бас маргаантай. Хүмүүс чинь тэгээд алдаа гаргадаг нь байгалиас заяасан сод билиг хойно нөгөө програм ч хүмүүсийн алдааг хуулна. За алдаа бага байна гэж гэгээлгээр хараад цааш бодож үзэхэд уг хөгжүүлсэн програм маань өөрийнх нь knowledge-с гадна өөр зүйл, өөр асуудалд бол яагаад ч ажиллаж чадахгүй. Тийм програм өөр салбарт хийх бол өөр нэг мэргэжилтэнг сансрын хөлөг хөлөглөж байгаад гэрийнх нь гаднаас тод гэрлээр хулгайлах хэрэгтэй болох юм шиг байгаа юм.
Ийм байдалд хүрлээ. Тооцооллын аргачлалаар шийдэж болох асуудал их. Цэвэр онолоор хөөгөөд хүмүүсийн толгой хүрдэггүй асуудал ч их. Хүмүүст жирийн тооцоолол хурдан хийх чадвартай компьютер, шийдэгдээгүй асуудлын талаарх дата их цуглагдаж байв бас. Өмнөх арга барилын алдаанаас сурах юм юу байв? Асуудлын шийдлийг ямар хэлбэртэй болгох хэрэгтэй байв?
Expert system, knowledge engineering-д бол хоёр том асуудал байсан нь:
1. Тооцоолол хийхэд хүндрэлтэй байдал. Зөв шийдэл сонгох тооцоолол хийхэд тооцооллын зай бол маш том, тэр үеийн компьютер байтугай одоо үеийн сайн компьютерүүд ч маш их хугацаа авахаар байв. Genetic algorithm, advanced algorithm гэх мэт арга ашиглаж тэр том зайг багасгаж тооцоололыг амарчлаад амарчлаад яг шаардлага хангахуйц биш л байж.
2. Зөвхөн нэг хүрээлэлд асуудал шийдэж байгаа баригдмал байдал. Уг нь Аладдины бирд шиг бүх зүйлд ажиллаж чадах байвал гоё биз дээ.
Дээрх хоёрын эхнийх бол угаасаа шийдэгдэж чадаагүй асуудал. Тэр үед ч, одоо үед ч шийдэх чадвартай хүн төрөөгүй. Нэгэнт тэр тийм хүнд учраас хоёр дахь асуудал дээр ажилласан нь дээр биз? Магадгүй арай амархан байх ч юм бил үү. Тэгээд бүх зүйл дээр ажиллах чадвартай хачин сайхан програм яаж хийх билээ? Нэгэнт хүмүүс өөрсдөө ингэ тэг гээд бичиж зааварчилгаа оруулж өгөөд бүтэлгүйтсэн хойно өөрөөр нь тэр хүссэн зүйлийг нь сургах гэж үзвэл дээр байх аа даа тийм биз? Яг нэг тийм хүн шиг тийм ээ. Хүний сурах үйл явцыг програмчлаад өгчихвөл нөгөө програм маань хүссэн зүйлийг сурна. Тэгэхээр хүн яаж сурдаг юм? Хүний тархи бол хэдэн жумаа мянган миний тоолж хэлж бичиж дурьдаж чадахааргүй их хэмжээний эсээс бүрдсэн том сүлжээ ба хамгийн жижиг биет эс бол энгийн бүтэцтэй хэдий ч хоорондоо сүлжигдээд ирэхээрээ ойлгоход хэцүү болчихдог эрхтэн. Үүнийг судлаад эхлэнгүүт хүн ямарваа нэг зүйлийг танихдаа, ямар нэг зүйлийг ойлгож хариу үйлдэл үзүүлж байхад тодорхой хэсэг эсийн бүлэг холбоо их ажиллагаатай байж байгаа нь анзаарагдаж.
Ок, бид тархины эс ньюрон бол энгийн гэдгийг бас тэр ньюронууд хоорондоо холбогдож хүний сурах, ямар нэг зүйлсийг таних зэрэг ид шидтэй юмыг хийгээд байгааг мэдэв. Энэ хоёр ажиглалт хүмүүсийг хиймэл неуроны сүлжээ програмчилж өөрөө явдаг машин, өөрөө орчуулдаг хөрвүүлэгч, өөрөө хүн таньдаг систем, өөрөө бургер таньдаг систем, өөрөө тоглож сурч хэнд ч дийлдэхээ байсан покер го шатар старграфт гэх мэт тоглоом тоглогч, өөрөө явдаг робот, өөрөө хувцас эвхдэг робот гэх мэт өөрөө гэдэг үг бичээд ард нь хүний хийдэг юмыг бичихэд тэрийг хийж чаддаг технологи хийх чадвартай болох хаалга нээсэн.
Тэгэхээр жирийн хэрнээ хүмүүст маш хэрэгтэй олон технологи хийхэд гол үүрэг гүйцэтгэсэн ньюроны бүтцийг математикийн хамгийн энгийн байдлаас эхлэн өрнүүлээд уг ньюроны сүлжээ яаж сураад байгааг баталж үзүүлье. Тэгээд энгийн ньюрон сүлжээг пайтон дээр бичиж яаж сүлжээ үүсгэж байгааг томёоны дагуу програмчилсан код танилцуулна. Сүлжээ бол MNIST гэх гар бичмэлийг таньж сурах систем. Математик, баталгаа гэхээр их айгаад байх зүйлгүй дээ. 24+55 хэд вэ гэдгийг (69 биш шүү, just in case) тооны машингүй боддог, n тоо гэхэд ямарваа дурын тоо гэж төсөөлж чаддаг байхад хангалттай. Яахав матрикс, вектор хоёрыг мэддэг байх бол ойлгоход хэрэгтэй. Бас функ, функцын график гэж юу гэдгийг мэддэг байвал зүгээр. Хэрвээ функцын график гэдгийг ямар нэг муруй мэтхэнээр төсөөлж буй бол тэрийг мэддэггүй л гэсэн үг шүү.
Математик
Функц гэж тэгээд юу билээ? Энэ бол ямарваа нэг өгөгдлийг өөр нэг олонлог (set) руу хуваарилдаг (mapping) математик хэрэгсэл. Нэг чухал чанар нь өгөгдлийн олонлогт буй өгөгдөл бүрийг давтагдашгүйгээр онцгой хуваарилдаг. Жишээлбэл:

 гэдэг функц байлаа гэхэд x-н утга бүр зөвхөн нэг л утга y-н олонлогт авна.
гэдэг функц байлаа гэхэд x-н утга бүр зөвхөн нэг л утга y-н олонлогт авна.  үед y бол зөвхөн 12 л байна. Энэ чанар нь бидний амьдрал дээрх бүхий л зүйлсийг математикт оруулж ирээд загварчилж болох боломж өгдөг. Жишээлбэл хотын замд хурд хэтрүүлж буй жолоочыг таних боллоо гэхэд тэр жолоочын хурдыг хэмжээд, хэрвээ хурд нь 60-с хэтэрч байвал хурд хэтрүүлсэн, хэтрээгүй бол хурд хэтрүүлээгүй гэх y-н хоёр утганд x буюу машины хурдыг оруулж үзэж болно. Машины хурд хэд ч байж болох ч байж болох хурд бүрт хэтрүүлсэн, хэтрүүлээгүй гэх хоёр утгын аль нэгийг л ногдуулж болох юм. x-н утга бүрт y-н ногдуулж байгаа утгын олонлогыг зураглаж үзүүлж байгаа нь бидний харж өссөн функцын график.
үед y бол зөвхөн 12 л байна. Энэ чанар нь бидний амьдрал дээрх бүхий л зүйлсийг математикт оруулж ирээд загварчилж болох боломж өгдөг. Жишээлбэл хотын замд хурд хэтрүүлж буй жолоочыг таних боллоо гэхэд тэр жолоочын хурдыг хэмжээд, хэрвээ хурд нь 60-с хэтэрч байвал хурд хэтрүүлсэн, хэтрээгүй бол хурд хэтрүүлээгүй гэх y-н хоёр утганд x буюу машины хурдыг оруулж үзэж болно. Машины хурд хэд ч байж болох ч байж болох хурд бүрт хэтрүүлсэн, хэтрүүлээгүй гэх хоёр утгын аль нэгийг л ногдуулж болох юм. x-н утга бүрт y-н ногдуулж байгаа утгын олонлогыг зураглаж үзүүлж байгаа нь бидний харж өссөн функцын график.

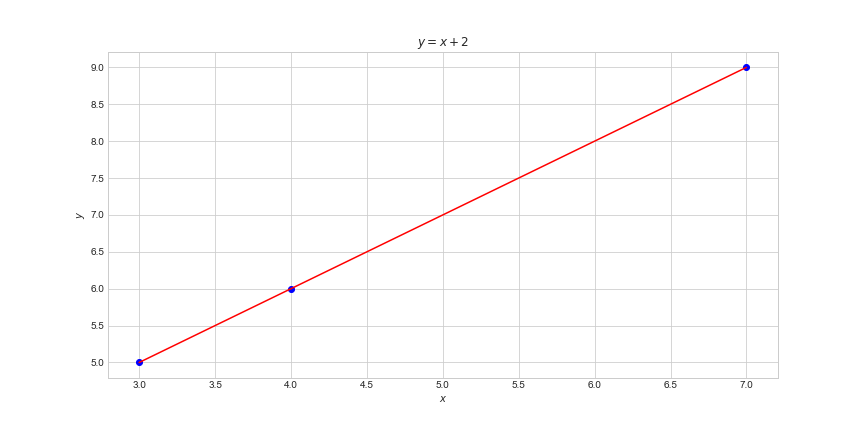
Функцын тусламжтайгаар амьдрал дээрх зүйлсийг өгөгдөл болгож математик загварчлалд оруулан янз бүрээр ашиглаж болно. Энийг ч эрдэмтэд, математикчид, статистикчид ашиглаж янз бүрийн дүгнэлт шинжилгээ хийж байв, хийж ч байна, хийсээр ч байх болно.

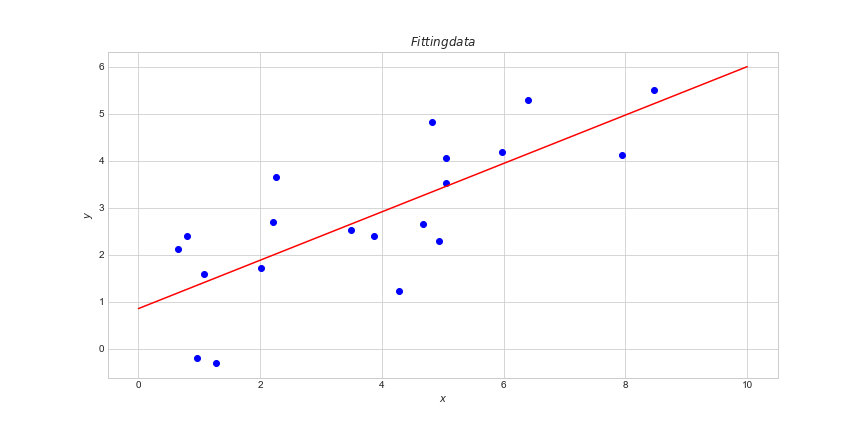
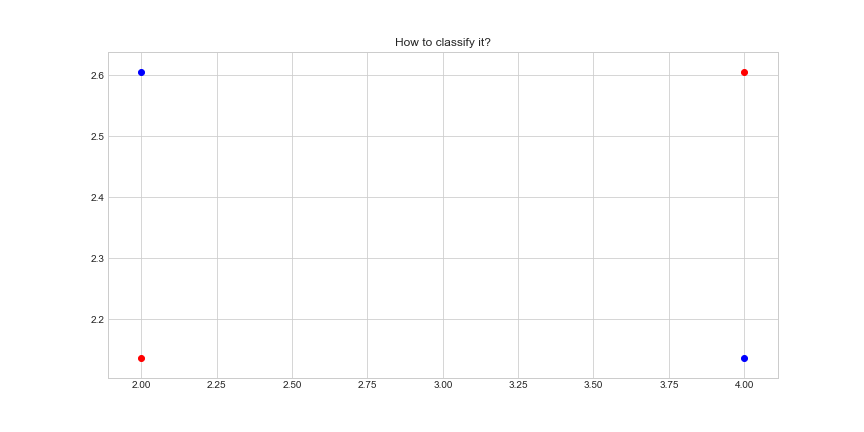
Харин хиймэл оюун ухаанд бол функцыг ашиглан датаг ангилах аргачлал хамгийн эхэнд хэрэг болно. Жишээлбэл:

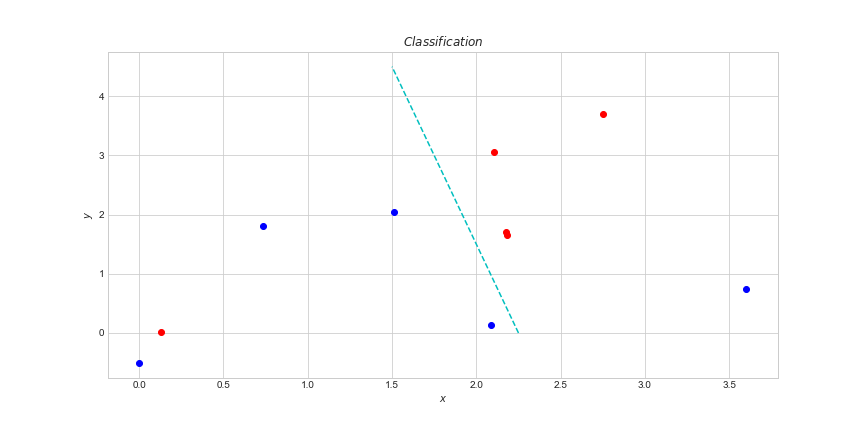
Дээрх зураг дээрх шиг хоёр өөр бүлэг өгөгдөл байгаад тэдгээрийг салгаж ангилах муж олох хэрэгтэй болов гэж бодъё. Тэр мужыг ногдуулж оноож чадах функц олно гэсэн үг л дээ. Энийг хийхэд ядах юмгүй байж. Бид ч ийм функц олж зурах даалгавар дунд сургуульда их хийдэг байсан даа, яагаав 
 график гээд л. Энд бол m коэффициент, b тоог олох хэрэгтэй. Регрэц анализ хийгээд тэр хоёрыг олчихно ядах юмгүй. Зарим нэг өгөгдөлд алдаа гаргана. Хааяа хааяадаа бүлгийн ангилал хийхдээ алдаа гаргана. Тийм ч учраас 70%, 80%-н нарийвчлалтай гэх мэтээр ярьна.
график гээд л. Энд бол m коэффициент, b тоог олох хэрэгтэй. Регрэц анализ хийгээд тэр хоёрыг олчихно ядах юмгүй. Зарим нэг өгөгдөлд алдаа гаргана. Хааяа хааяадаа бүлгийн ангилал хийхдээ алдаа гаргана. Тийм ч учраас 70%, 80%-н нарийвчлалтай гэх мэтээр ярьна.
Ньюрон
Нөгөө тархины эс ньюрон ч яг ийм бидний мэдэх функцтэй адил. Өөрийн гэсэн коэффициенттэй, хувьсагчтай, бас нэмэгчтэй. Хувьсагчыг (input) бидний оруулж тооцоо хийх дата, коэффициентуудыг (weight) сургалтын чадвар сайжруулахад зориулж ашиглах бол нэмэлтийг (bias) бол функцын мужаа тэг дээрээс эхлүүлээд байхгүй гэх оролдлого. Энэ bias бол их чухал биш ба би python-д бичсэн сүлжээнд ашиглаагүй бол pytorch-оор бичсэн сүлжээнд ашигласан. Ашиглах бол ямар ч хамаагүй тоо таамгаар оноочихно. Энд анхаарлаа хандуулах гол зүйлс нь weight, болон input юм. Input бол бидний оруулж өгөх янз бүрийн дата учраас бид тэр утгуудыг өөрчилан удирдаж өөрийн системээ сургаж болохгүй. Тэгэхээр weight-үүдийн утгыг өөрчилж машин сургалтаа явуулж системийнхээ удирдаж функцүүдийг өгөгдлийг зөв ангилуулна.
Ерөнхийдөө хамгийн энгийн ньюрон бол өөртөө өгөгдөл аваад, тооцоолол хийгээд, үр дүнгээ гаргаад явуулчихдаг зохион байгуулалттай. Яг биологийн талаас нарийн бүтэц бол dendrite- р өгөгдөл болох эсийн урвалууд явагдаж эсийн төв cell body-д очоод тэндээс ямар нэг хязгаарлалтаас (threshold) хамаарч нэг бол харвалт өгнө (fire) эсвэл тэндээ үлдэнэ. Харвалтыг axon-оор дамжуулан дараагийн ньюроны сүлжээ урвал үргэлжлэгдэж явагдана. Бидэнд бол хамгийн энгийн хэлбэр буюу өгөгдөл авдаг, өгөгдөл дээр тооцоолол хийдэг, тэр тооцооллоо өөрөөсөө гаргаж дараагийн ньюрон руу илгээдэг байдал хэрэгтэй. Зургаар харуулбал:

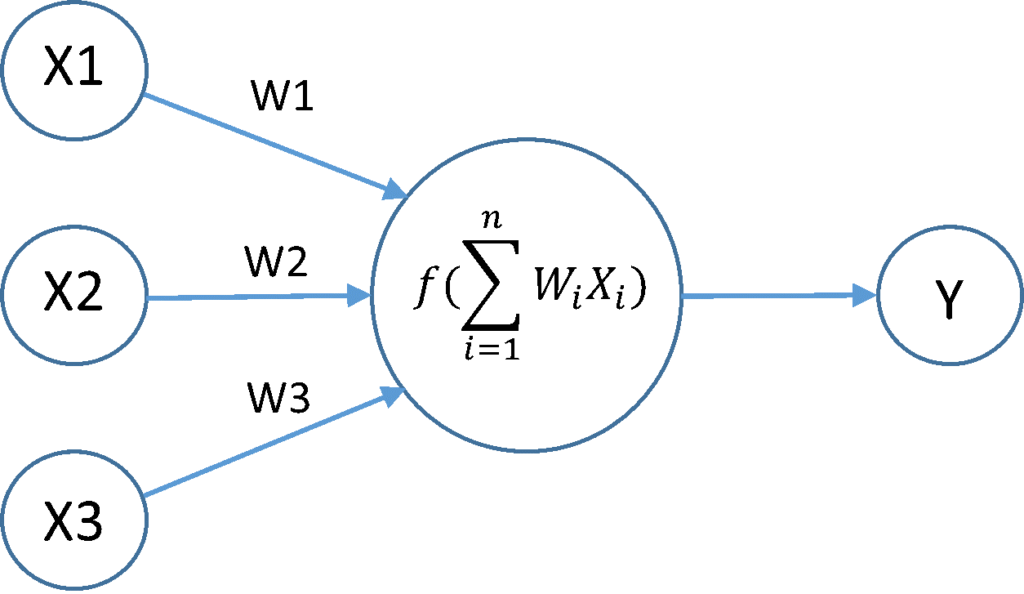
Stackoverflow
Дээрх зурагны зүүн талд яг биологийн нэгж ньюрон ямар байхыг харуулсан бол баруун талд нь үүнийг хэрхэн математик загвар болгон буулгаж авч байгааг бүдүүвчилж харуулав. Ньюрон олон w-ээр өөр дээрээ өгөгдөл авч буй ба тэр өгөгдлүүдээ нийлүүлээд тэрийгээ activation function гэх нэг функц рүү өгөгдөл болгон оруулж уг нэгж ньюроны гаралт утга ямар байхыг тооцоолж байгаа юм. Ньюрон өөртөө n тооны өгөгдөл хүлээж авах ба бүх өгөгдлөө зүгээр л хооронд нь нэмж өөр дээрээ хүлээж авч буй өгөгдлийг тооцно. Энд шугаман тэгшигтэл яаж хэрэглэгдэж байгаа харуулбал:
(1.1) ![\[ y = w*x \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-d8a80132e25f0928f17b94775c78e51b_l3.png?resize=86%2C14)
![\[ y = w*x \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-d8a80132e25f0928f17b94775c78e51b_l3.png "Rendered by QuickLaTeX.com")
(1.2) ![\[ y = w_1*x_1 + w_2*x_2 \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-003fa596f8ff247206a006947593f3ea_l3.png?resize=195%2C18)
![\[ y = w_1*x_1 + w_2*x_2 \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-003fa596f8ff247206a006947593f3ea_l3.png "Rendered by QuickLaTeX.com")
(1.3) ![\[ y = w_1*x_1 + w_2*x_2 + \dots + w_n*x_n \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-0b0abf0d6132f1a4c383de7e07d47d94_l3.png?resize=339%2C18)
![\[ y = w_1*x_1 + w_2*x_2 + \dots + w_n*x_n \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-0b0abf0d6132f1a4c383de7e07d47d94_l3.png "Rendered by QuickLaTeX.com")
(1.1) бол бага ангийн шугаман тэгшигтэл. (1.2) бол хоёр хувьсагчтай тэгшитгэл болгож буй бол (1.3) ерөнхийлөөд дурын n тооны хувьсагчтай хэлбэр.
За энд өгөгдлүүдийн талаар юу бодож болох вэ? Янз бүрийн хэмжээстэй өгөгдөл байх нь мэдээж тиймдээ ч бид n тооны хэмжээстэй гэж үзсэн. Өгөгдлийн хэмжээнээс хамаарч олон зэргийн шугаман тэгшитгэл бүхий функц үүсгэж ньюронд ирж буй өгөгдлүүдийг тооцно. Ганц өгөгдөлтэй бол шулуун шугаман тэгшигтэлийг бага ангийн хүүхэд ч зураад харчихна. Хоёр өгөгдөлтэй бол хавтгайн шугаман тэгшитгэл болгоод дунд ангийн хүүхэд ийм тийм гээд бодоод гаргачихна. Гурваас дээш гараад ирэхээр хүн энийг төсөөлж чадахгүй. Яагаад гэхээр сармагчингаас их ялгаагүй бидний тархи нүдэнд харагдаж байгаа зүйлийг л боловсруулж, тэрэнд тохируулж сэтгэдэг дутагдлаас болоод 4 хэмжээст дүрс гэдэг юмыг дүрсэлж чадахгүй болохоор тэр. Үүнд функцын тодорхойлолтыг санах хэрэгтэй. Функц бол өөрт өгөгдсөн утгыг өөр нэг олонлогын муж руу ногдуулж тооцоо хийдэг хэрэгсэл. Тэгэхээр хэдэн ч өгөгдөл функцт оруулж тооцоо хийсэн хаа нэгтээ ямар нэг мужыг уг функц маань олоод л байгаа юм хөөрхий гэж бод.
Pre-processing
Харин өгөгдөл болж тооцогдох тооны хувьд бол ямар ч тоо байж болох вэ? Хүмүүсийн цалинг оруулна гэвэл хэдэн мянгаас эхлээд хэдэн сая хүртэл, хүмүүсийн өндөр гэвэл хэдэн десиметр, химийн урвалын хэмжээс оруулбал 10-н хэдэн арван хасах зэрэгт тоог орох бол физикийн хэмжээсүүд 10-н хэдэн зуун зэрэгт тоо байна бас тэгээд УБ Комедичдийн ёс суртахууныг хэмжиж тооцоонд оруулна гэвэл нэлээн бага тоо хэрэгтэй. Тэгэхээр энэ асуудлыг яаж шийдэх билээ? Бүх төрлийн зүйлд ажиллах програм бүтээх гэж буй бол ийм өгөгдлийн таамаглашгүй байдлыг шийдвэрлэх хэрэгтэй. Үүнийг програмд өгөгдөл оруулж тооцоо хийхээсээ өмнө бүх төрлийн датаг нэг ижил маягт оруулдаг нэмэлт ажиллагаа (pre-process, normalise) нэмж болно, ньюронд тооцоо хийгээд гаргахдаа датаг нэг маягт оруулж тооцоо хийж болно эсвэл аль алийг нь ашиглаж болно. Ихэнх загварт аль алийг нь ашигладаг. Яагаад гэхээр шинэ асуудал шийдэх, огт харагдаж байгаагүй дататай тооцоолол хийх зэрэгт нэг хэвд оруулсан байдал нь тооцоо хийхэд хялбар болгож өгнө.
Нэг маягт оруулах гэдэг маань датаг илэрхийлэх байдлыг 0 – 1н хооронд болгох ч юм уу гэж ижил илэрхийллээр төлөөлж болгох байдал. Ньюронд бол энийг өгөгдөл тооцоолох функц (activation function) дээр хийж болно. Гэхдээ өгөгдөл оруулж тооцоо хийхээсээ өмнө уг датагаа normalise хийгээд өгчихвөл зүгээр. Яагаад гэхээр бүх ньюрон дээр ижил хэмжүүртэй байвал тооцоо хийхэд амар бас ярьж ойлголцоход ч амар. Харин саяхан тас хийгээд дурьдсан activation function гэж юу билээ?

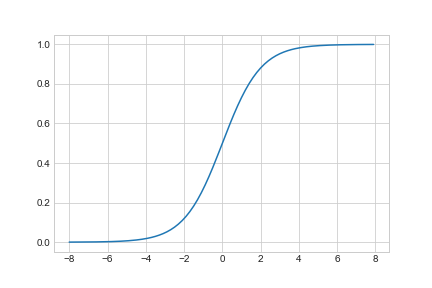
Энэ бол нөгөө ньюронд оруулсан өгөгдөлд тооцоо хийдэг функц. Шийдэх гэж буй асуудлаасаа хамаараад олон янзын функц ашиглаж болох ба өөрөө шинэ функц оруулж ирж ашиглаад докторын зэрэг авсан ч болно. Тэгэхээр activation function-д ерөнхийдөө step, sigmoid, relu, tanh гэх зэрэг олон функц бий. Эдгээр функц бүр өөрийн гэсэн томъёолол, давуу тал, сул тал байх ба хамгийн элбэг ашиглагддаг нь sigmoid болон relu. Энэ нийтлэлд бол sigmoid-г ашиглана. Яагаад гэдэг нь ньюрон сүлжээг сургах томъёололын гаргалгаа хийж байхад тод харагдана. Sigmoid функцын хэлбэр дээрх зураг дээрх шиг ба томъёо нь ч бас доор буй. Гол чанар нь бол ямар ч тоог өгөгдөл болгож өгсөн 0 – 1 н хооронд шахагдсан тоо гаргана. Ок, нэг хэвд орох нь ч орж, харин дутагдал юу байна? Функцын графикын хэлбэр харвал их шахагдсан хэлбэр нь зарим төрлийн датаг илэрхийлэхэд хүндрэлтэй байдалд хүргэнэ. Хэрвээ дата маань тархалтын хувьд нэг тал руу хэвийсэн бол sigmod функц том өгөгдлийн зайд их бага ялгаатай хариу гаргана. Тэр нэг тиймэрхүү хэдий ч бүх тоог 0 – 1 н хооронд шахаж өгч байгаа нь бас өөр нэг математикийн хэрэгсэл ашиглах боломж гаргаж ирнэ. Магадлал.
Өгөгдсөн датаны тархалтаас хамаарч sigmoid-н гаралт хамаарахаас эхлээд өөр бусад зүйлд магадлалын онолын хэрэглээ машин сургалтанд их. Хэдий тийм ч энэ нийтлэлд магадлалын талаарх их гүнзгийрүүлж ярилгүйгээр ингэсхийгээд дурьдаад л орхино. Үүнээс чухал зүйл нь чухам яаж энэ ньюроны энгийнээс энгийн шугаман тэгшитгэл гүний сургалт хийх систем угсрахад оролцоод байгаа байдал.
Шугаман тэгшигтэл
Шугаман тэгшитгэл ямар байдаг билээ? Шугаман. Ямар байдлаар датаг хувааж байна? Шулуун шугамаар. Алдаа байна уу? Маш их. Бүүр маш их. Тэгээд яагаад илүү нарийн функц ашиглаад илүү нарийн заагтай муж үүсгэж болохгүй гэж? Наанадаж л дунд сургуульд үздэг параболь муруй гэхэд л шугаман тэгшитгэлээс хамаагүй нарийн заагтай муж үүсгэж болно шүү дээ. Мэдээж болно, тиймэрхүү нарийн математикт суурилсан аргачлалуудаас shallow learning algorithm-ууд суурилсан байдаг. Тэр аргачлалууд яг л ньюрон сүлжээ шиг үр дүн гаргах уу гаргана. Гэхдээ чи өнөөдөр хүмүүс математикчилсан машин сургалт гэж их ярьж байна уу эсвэл хиймэл оюун ухааны сүлжээ гэж их ярьж байна уу?
Мэдээж бид бүгд хариултыг нь мэднэ. Ньюроны сүлжээ бусад аргачлалуудаас давуу гарах нэг чадвар байдаг нь өгөгдсөн датаны хэмжээгээр өөрийнхөө сурах чадварыг нэмэгдүүлдэг байдал. Shallow machine learning аргачлалууд одоо сайндаа 80, 90 хувь орчим хүрээд л зогсонги байдалд орж эхлэх бол ньюроны сүлжээ их дата оруулж сургах тусам өөрийнх нь сурах байдал сайжирч 95, 98 хувь гэх мэт өссөөр л байдаг. За математикийн нарийн аргачлалууд тийм алдаатай юм бол чухам яаж шугаман тэгшитгэлийг ньюрон сүлжээ ашиглаж тэдгээр shallow machine learning аргачлалаас илүү нарийн үзүүлэлттэй байгаа юм? Бас жирийн шугаман тэгшитгэлээр салгаж чадахгүй дата ч байна. Жишээлбэл доорх датаг салгах шугаман тэгшитгэл байх боломжгүй гэдэг нь батлагдсан зүйл.

Хариулт бол энгийн. Олон ньюронг давхарлаж үүсгэх. Ньюрон бүр шугаман тэгшитгэлээр ямар нэг илэрхийлэх бол сүлжээнд буй ньюрон бүрийн илэрхийлж буй муж бүрийг нийлүүлж муж үүсгэх юм. Тэгэхээр дээрх шиг ганц тэгшитгэлээр салгаж болохгүй датаг хоёр шугаман тэгшитгэлээр л салгаад ангилж болох бол илүү нарийн датаг ангилахдаа маш олон ньюрон ашиглаж ямар ч математик тэгшитгэл гаргаж ирж чадахааргүй нарийн муруйг үүсгээд байгаа юм.

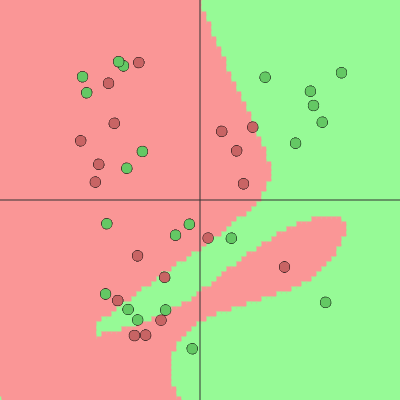
https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
Жишээлбэл дээхр зурагт маш олон шугаман тэгшитгэлийн нийлүүлж өгөгдөл датаг хоёр салгах гэж оролдож буй байдал харагдаж байна. Мэдээж олон шугаман мужыг нэгтгэж тэднийг холбох тусам улам нарийн олонлогийн зураглал харагдана. Тиймдээ ч ньюрон хэдэн зуугаас эхлээд хэдэн сая ньюрон бий. Яг эндээс эхэлж хэрхэн ньюронуудыг хооронд нь холбож сургах вэ гэдэг асуудал гарч ирнэ. Тэрийг ярихаас зайлшгүй мэдэх ёстой өмнө гялс вектор, матрикс дурьдахад.
Вектор, матрикс
Бид ерөнхийдөө нэг гарын хуруунд багтаж байх хувьсагчдыг харьцуулаад, энд тэнд нь оруулаад тэгшигтэл бодчихно. Яагаав 
 гэх маягтай тэгшигтэл. Заримд маань ярьвигтай харагдаж ч магад хэдий ч амьдралд тохиолдож болох олон асуудалд тавхан хувьсагчаас сонголт хийж илэрхийлэхэд хэцүү. Жишээлбэл доорх зургыг хар.
гэх маягтай тэгшигтэл. Заримд маань ярьвигтай харагдаж ч магад хэдий ч амьдралд тохиолдож болох олон асуудалд тавхан хувьсагчаас сонголт хийж илэрхийлэхэд хэцүү. Жишээлбэл доорх зургыг хар.


https://en.dopl3r.com/memes/dank/my-wife-asked-me-which-one-i-like-more/29349
Амьдралд таарах асуудал бүрийг шийдэхийн тулд уг асуудлаа төрөлжүүлээд, төрөл бүрт нэг хувьсагч өгчихвөл зүгээр. Тэгэхэд вектор ашиглах нь их таатай байгаад байгаа юм. Вектор бол зүгээр нэг цуваа тоо. Дунд сургуульд биеийн тамирд бүгдээрээ жагсдаг даа. Тэр 1-г харьцах нь ангийн хүүхдийн тооны хэмжээс бүхий 
 вектор илэрхийлэл. Яагаад? Нэг нэгээрээ жимбийж зогсоод n тооны хүүхэд цуваа болчихсон учраас. Датандаа оруулж болох төрөл бүрийн хувьсагч бүрийг орж бодоод тэрийгээ вектор болгох бол машин сургалтанд их хийнэ. Мэдээж
вектор илэрхийлэл. Яагаад? Нэг нэгээрээ жимбийж зогсоод n тооны хүүхэд цуваа болчихсон учраас. Датандаа оруулж болох төрөл бүрийн хувьсагч бүрийг орж бодоод тэрийгээ вектор болгох бол машин сургалтанд их хийнэ. Мэдээж  хэмжээтэй вектор байж болж байгаа бол
хэмжээтэй вектор байж болж байгаа бол  хэмжээстэй ч вектор байна. Жишээлбэл би шоколад аваад идэхдээ шоколадныхаа гаднах цаасыг сайхан хуулж авч байгаад л эгнээ эгнээгээр нь хугалж иддэг. Ямар хэрэм байгаа биш шоколадны өнцөгөөс нэг нэгээр нь мэрдэггүй. Хүн бол л тэгсхийгээд шоколадыг эгнээ эгнээгээр нь хугалж аваад иддэг л байлгүй. Энд бол шоколадаа вектор хэлбэрээр идэж байгаа юм. N дөрвөлжин бүхий нэг эгнээ шоколад тийм ээ. За тэгээд гол зүйл нь юу вэ гэхээр шоколад авлаа, эгнээгээр нь хугаллаа, тэрийгээ ам руугаа. Буцаад вектор луу ороход нэг хэмжээст вектор бол ийм хоёр төрлөөр байна. Эдгээрийг дурын тоогоор үржүүлэх бол зүгээр векторын гишүүн болгоныг үржүүлэхэд хангалттай бол векторыг вектороор үржүүлэхэд хоёр янзын үйлдэл бий.
хэмжээстэй ч вектор байна. Жишээлбэл би шоколад аваад идэхдээ шоколадныхаа гаднах цаасыг сайхан хуулж авч байгаад л эгнээ эгнээгээр нь хугалж иддэг. Ямар хэрэм байгаа биш шоколадны өнцөгөөс нэг нэгээр нь мэрдэггүй. Хүн бол л тэгсхийгээд шоколадыг эгнээ эгнээгээр нь хугалж аваад иддэг л байлгүй. Энд бол шоколадаа вектор хэлбэрээр идэж байгаа юм. N дөрвөлжин бүхий нэг эгнээ шоколад тийм ээ. За тэгээд гол зүйл нь юу вэ гэхээр шоколад авлаа, эгнээгээр нь хугаллаа, тэрийгээ ам руугаа. Буцаад вектор луу ороход нэг хэмжээст вектор бол ийм хоёр төрлөөр байна. Эдгээрийг дурын тоогоор үржүүлэх бол зүгээр векторын гишүүн болгоныг үржүүлэхэд хангалттай бол векторыг вектороор үржүүлэхэд хоёр янзын үйлдэл бий.

 векторыг вектороор үржүүлэхэд хоёр векторын гишүүн бүрийг харгалзаж үржүүлээд бүгдийг нь нийлүүлж нэмээд нэг жирийн тоо гарна
векторыг вектороор үржүүлэхэд хоёр векторын гишүүн бүрийг харгалзаж үржүүлээд бүгдийг нь нийлүүлж нэмээд нэг жирийн тоо гарна  . Энэ үржвэрийг (dot product) ньюроны өгөгдөл дамжуулахад ашиглана. Weight-үүдийг
. Энэ үржвэрийг (dot product) ньюроны өгөгдөл дамжуулахад ашиглана. Weight-үүдийг  гэх вектор, input-г
гэх вектор, input-г  гэх вектор болгоод dot product хийхэд ньюроны өгөгдөл гараад ирж байгаа биз.
гэх вектор болгоод dot product хийхэд ньюроны өгөгдөл гараад ирж байгаа биз.
За вектор нэг иймэрхүү бол энийг илүү жаахан өргөжүүлээд матрикс болгочихдог. Вектор эсвэл  гэх хэмжээст л баригдаж байсан бол матрикс
гэх хэмжээст л баригдаж байсан бол матрикс  ,
,  буюу дурын хэмжээстэй. Хоёр матриксын үржвэр ч арай өөр болно. Жишээлбэл , бол
буюу дурын хэмжээстэй. Хоёр матриксын үржвэр ч арай өөр болно. Жишээлбэл , бол  матрикс үүсгэх бол, болон гэх матрикс-вектор үржвэр
матрикс үүсгэх бол, болон гэх матрикс-вектор үржвэр  гэх вектор,
гэх вектор,  болон гэх вектор-матрикс үржвэр гэх вектор, болон
болон гэх вектор-матрикс үржвэр гэх вектор, болон  гэх матрикс-матрикс үржвэр
гэх матрикс-матрикс үржвэр  гэх матрикс болно. Нэг зүй тогтол байгааг анзаарсан бол хоёр үржвэрийн голын хэмжээс яг таарах ёстой ба тэр хэмжээс үржвэрийн дүнд алга болоод хоёр захын хэмжээс нь үлдчихэж байгаа.
гэх матрикс болно. Нэг зүй тогтол байгааг анзаарсан бол хоёр үржвэрийн голын хэмжээс яг таарах ёстой ба тэр хэмжээс үржвэрийн дүнд алга болоод хоёр захын хэмжээс нь үлдчихэж байгаа.
Сургах явц
Зиак одоо нэгэнт ньюрон сургах явцыг ойлгоход хэрэгтэй зүйлсийг нухацтай тайлбарласан хойно одоо сургалтын процесоо харж үзье. Ньюрон сүлжээ бол supervised machine learning учраас сургах процесст ашиглах датагаас (training data) гадна хүссэн үр дүн ийм гэж зааж өгөх зориулалттай training label/target болон угсарсан сүлжээ хэр сайн ажиллаж байгааг шалгах зориулалттай test data, test label/target гэх дата бий. Өөрөөр хэлбэл ньюрон маань training data-г өөртөө өгөгдөл болгож оруулаад training label-г бүрэн таньж чаддаг болтолоо суралцах юм. Нэгэнт тэгж сурсан сүлжээгээ test data дээр туршиж үзэж сургалтанд огт ашиглагдаагүй байгаа датанд хэр сайн ажиллаж байгааг хэмжих юм. Чухам яагаад ингэж байгаа юм гэхээр машин сургалтын аргачлал маань өөрөө алгоримтчилсан аргачлал биш учраас асуудлыг шийдэхэд туслах хэсэг дата цуглуулаад, түүнийгээ уг асуудалтай холбоотой амьдрал дээр таарч болох датаны нэг хэсэг (sample set) гэж үзээд тэр датанд буй хэв шинжийг сурахыг хичээх аргачлалтай болохоор тэгж байгаа юм. Энгийнээр хэлбэл нэг төрлийн датаны тодорхой нэг хэсэг олонлогыг ашиглаж тухайн датаны ерөнхий хэв шинжийг сурч авах бол машин сургалтын аргачлалын гол санаа.
Тэгэхээр үүнийг гаргаж ирж харуулахын тулд эхэлж сүлжээнд чухам ямархуу тооцоолол явагдаж байгаа талаар яриад, энгийн жишээний талаар ярьж уг процессыг ерөнхий ойлголтыг ухааруулаад тэрний дараа уг математик суурь томъёо яаж гарч ирж байгааг харуулна. Эхний ньюрон бол input layer, сүүлийнх output layer бол дунд хоёр бол hidden layer. Input layer бол өөрт ирсэн өгөгдлийг цааш дамжуулах үүрэгтэй бол output layer өөрт ирсэн өгөгдлийг хүлээж авч тооцоо хийгээд өө би өөр дээрээ нэг ийм юм авчихлаа, тооцооны үр дүн нь энэ гээд сүлжээний тооцооллын үр дүнг гаргах үүрэгтэй. Харин hidden layer- ууд бол сүлжээний хэрхэн сурч байгаа хэсэг юм. Тэнд сүлжээнд хэрэгтэй чадваруудыг сурж авна. Орчин үеийн лаг системүүд бол хэдэн сая hidden layer-тай гэх домог хүмүүс ярьдаг. Харин энэ нийтлэлд ашигласан цэвэр python-д бичсэн систем 100 hidden layer, 784 input layer, 10 output layer-тай бол pytorch адилхан 784 input, 10 output, 200 hidden layer-тай. Яг кодыг хармаар бол эндээс jupyter-ээр хараад, өөрөө ажиллуулж үзэж болно. Код бичихэд хэд л бол хэдэн ньюрон оруулж бичиж болох ч бичиж тайлбарлахад бол 
 хэмжээстэй энгийн сүлжээ хангалттай.
хэмжээстэй энгийн сүлжээ хангалттай.
Эдгээр ньюронууд нэрээр өөр боловч бүтцийн хувьд бүгд адил. Өгөгдөл өөр дээрээ хүлээж авангуутаа тэрийгээ өөрт ноогдсон weight-ээр dot product хийгээд activation function руу явуулахад activation function тэрэнд нь өөрийнхөө тооцооллоо хийгээд гарсан үр дүнг дараагийн ньюрон руу илгээнэ. Нөгөө ньюрон яах вэ? Бас л адилхан явуулсан өгөгдлийг нийлүүлээд өөрийнхөө activation function руу явуулна. Тэндээ тооцоо хийгдээд дахиад л дараагийн ньюрон руу гаргана. Ньюрон маань input, output layer биш л бол яг энэ ижил ажиллагаатай. Уйтгартай нь аргагүй ганц зүйлийг хийдэг боловч энэ байдал нь ньюронг илүү хүчирхэг, уян хатан болгож байгаа юм. Ямар өгөгдөл өгөхөд ямархуу гаралт гаргах нь тодорхой болохоор hidden layer-үүдийн хооронд нь холбогдож байгаа байдал болон activation function-д өөр олон функц нэмэх зэргээр ньюрон сүлжээний зохион байгуулалтыг өөрчилж нөгөө RNN, CNN гэх мэт тусгай зориулалттай хиймэл оюун ухааны сүлжээ үүсгэж байгаа юм. Түүнээс хийх үйлдэл бол бүгд адил: Өөртөө өгөгдөл авна, нийлүүлж байгаад өөрийнхөө weight-тэй нийлүүлж нэмээд activation function руу явуулна. Энгийн тийм биз? Томъёолоод бичвэл ингэж харагдана.
(2.1) ![\[ $x = W\times i$ \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-9b228b5af002d184c33ab11432cbc05d_l3.png?resize=86%2C17)
![\[ $x = W\times i$ \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-9b228b5af002d184c33ab11432cbc05d_l3.png "Rendered by QuickLaTeX.com")
(2.2) ![\[ $o = Sigmoid(x)$ \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-b58805011c7fb114cd1fcda956447ce2_l3.png?resize=142%2C23)
![\[ $o = Sigmoid(x)$ \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-b58805011c7fb114cd1fcda956447ce2_l3.png "Rendered by QuickLaTeX.com")
Дотоод тооцоолол бол ийм энгийн. Харин өгөгдөл оруулах input layer-с эхлээд эдгээр гинжин тооцоолол хийж явсаар байгаад өгөгдлийн хариу гаргах output layer-д ирлээ. Хэрвээ өгөгдөл датагаа сүлжээнд сургах гэж оруулахаасаа өмнө normalise хийсэн бол бүх датаны утга 0-1н хооронд байх учраас аль ч ньюронд тооцоо хийсэн гарах үр дүн хоорондоо төстэй. Гэхдээ тэгээд яаж “сураад” билээ?
Хүн ер нь яаж сурдаг билээ? Хэрвээ ньюроныг хүн шиг сурдаг гэж үзвэл манайхан шиг шинэ зүйл хийж эхлэхийн өмнө өөрөө гэнэтхэн төгс болохыг хүлээж суугаад, хаа газар монгол гений IQ өндөр байгааг харуулна гэж ам бардам үглэсээр дэмий суугаад, хэн нэгэн нь чиний сурах юмыг өөрөөс чинь өмнө хийгээд өгөхийг хүлээгээд суусаар л байх уу? Би чадна, амархан гэж амаараа ярьж суунгаа өөрийнх нь хүссэн зүйлийг хүнээр хийлгүүлэх гэж онлайн тэмцэл хийх гэх мэтийн хэрэггүй юм хийж суух уу? Мэдээж үгүй. Шинэ зүйл сурч байгаа учраас аль болох хурдан том алдаа гаргаж хийж эхлээд яваа яваандаа тэр алдаагаа багасгаж өөрийгөө танаг орох хүртэл ажиллаж суралцана гэх амьдралын энгийн зарчим энэ ньюрон сүлжээнд ашиглагдана. Хамгийн эхний ньюронууд болох input layer-н weight-үүдийг хаа хамаагүй (random) тоо оноож өгч өөр дээрээ өгөгдөл хүлээж аваад тоцооллоо layer-үүд рүү шилжүүлэн давалгаалуулчихна. Тэр давалгаан дунд хэдэн hidden layer-ууд нь баахан тооцоолол хийж хийж эцсийн эцэст output layer-д очиж өгөгдөл болгож оруулсан датаны үр дүн гарч ирнэ. Тэнд эхний ээлжинд ямархуу үр дүн гарах вэ гэхээр мэдээж хэнд ч хэрэггүй үр дүн гарна. Яагаад гэхээр input, hidden, output layer гээд бүгд хаа хамаагүй weight-тэй эхэлж тооцоо хийгдсэн учраас сүлжээний үр дүн бол ямар ч оновчгүй, байх ёстой үр дүнгээс хол буудсан байна.
Хүссэн үр дүнгээс хэр хол буудсан байна гэдгээ сургалтын датанд ялгаж авсан training target-н тусламжтай тооцоолно. Сүлжээний гаргаж ирсэн хариуг training target-аас хэр зэрэг ялгаатай байгааг тооцож үзэхэд хэр зэрэг алдаатай байгаа нь харагдана. Output layer өөрийнхөө алдааг target-тай харьцуулж олоод, тэрийгээ өөрийнхөө өмнөх hidden layer-тай харьцуул гээд явуулчихна. Тэр hidden layer нь ямархуу алдаа гаргах хэрэгтэй байснаа хүлээж авангуутаа өөрийнхөө ньюронд гаргасан алдаагаа тооцоод өмнөх hidden layer луу тэрийг явуулна. Энэ мэтчилэн явсаар байгаад input layer дээр ирнэ дээ. Ингэж ямарваа юм хоорондоо дамжуулж яваад байгааг англиар propagate гэх ба алдаа дамжуулж буй учраас error propagating гээд тэр алдаагаа output-аас input layer луу буцааж дамжуулж буй учраас back-propagation algorithm гээд нэртэй болчихож байгаа юм.
Нэгэнт output-аас эхэлж тооцогдсон алдаа буцаж давалгаалсаар байгаад input layer-д ирээд тэндээс алдаа засах тооцоолол хийгдэж буцаад input-аас output хүрэх тооцооллын давалгаа эхэлж байгаа юм. Ийм байдал хэдий хүртэл үргэлжилж болох вэ? Тухтай бодоод үзэхэд эхлээд ямар ч алдаагүй болтол сургалтаа үргэлжлүүлж болно. За тийм төгс болох боломжтой юу? Хэрвээ тийм алдаагүй болгох боломжтой асуудал байсан бол алгоритмд суурьлсан аргачлал олчих байсан. Тиймээс энэ сургалт маань 100% алдаагүй болтол ажиллана гэх бодол их гэнэн бодол. За тэгвэл 5%-н алдаа гаргах хүртэл буюу 95%-н амжилттай тооцоо хийдэг хүртэл сүлжээгээ сургаж болно. Яахав мэдээж болно. Гэхдээ тийм болтол хэр удаан хүлээх вэ? Хэр удаан сургалт явах вэ гэдэг энэ асуултанд хариулт өгөх хэцүү. Хэдэн цагаас эхлээд хэд хоног ажиллах бол энгийн үзэгдэл. Тиймд хүмүүс сургалтыг туршиж үзэхдээ тэдэн удаа input-output-input хүртэлх энэ явцыг гэж тоо өгч ажиллуулдаг. Үүнийг epochs гэдэг. Энэ тоо 100 бол тэр чинээ сургалтын эргэлт явагдаж, тэдэн удаа сүлжээ өөрийгөө сайжруулах гэж оролдоно. Энгийн үү энгийн. Гэхдээ эрдэмтэд энийг нээж, бодож сурах гэж 30н жилийг зориулсан юм шүү.

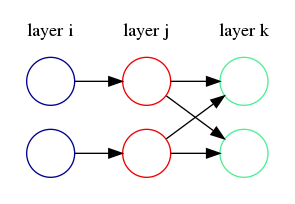
Example: Neural computation
Жишээ болгож гурван layer-тай сүлжээ авч үзье. Энэ бүрэн биш хэдий ч input -аас output хүртэл ирсэн өгөгдөл бүрийг давалгаалж тооцоолоод forward propagation хийж байгаа болон output layer – аас input layer хүртэл error – ыг буцааж давалгаалан back propagation хийж байгааг тайлбарлахад сайхан тохирно. За сүлжээ маань 
 гэсэн гурван layer- тай. Ньюронууд бүгд өмнөх layer-н бүх layer-аас өгөгдөл хүлээж авах бөгөөд тэрийг сумтай зураасаар тэмдэглэв. Тэгээд бодоод үзэхээр ямарваа ньюроны weight маань өмнөх layer тоо ба өөрийн layer-н тоо гэсэн хэмжээс бүхий матрикс болж таарна. Энд векторын жижиг үсгээр, матриксыг том үсгээр, бичигдсэн үсгийн доор аль layer-аас аль руу чиглэсэн давалгааг тэмдэглэж үсгүүдийг нь бичив.
гэсэн гурван layer- тай. Ньюронууд бүгд өмнөх layer-н бүх layer-аас өгөгдөл хүлээж авах бөгөөд тэрийг сумтай зураасаар тэмдэглэв. Тэгээд бодоод үзэхээр ямарваа ньюроны weight маань өмнөх layer тоо ба өөрийн layer-н тоо гэсэн хэмжээс бүхий матрикс болж таарна. Энд векторын жижиг үсгээр, матриксыг том үсгээр, бичигдсэн үсгийн доор аль layer-аас аль руу чиглэсэн давалгааг тэмдэглэж үсгүүдийг нь бичив.  layer-т ирж буй өгөгдлүүдийг тооцож үзээд, үүнийг тухай layer-н activation function-аар гаралтын утгыг бодож үзвэл:
layer-т ирж буй өгөгдлүүдийг тооцож үзээд, үүнийг тухай layer-н activation function-аар гаралтын утгыг бодож үзвэл:
(3.1) ![\[ $\begin{pmatrix} w_{1_,i} & w_{1_,j} \\ w_{2_,i} & w_{2_,j} \end{pmatrix} \times \begin{bmatrix} i_{i_1} \\ i_{i_2} \\ \end{bmatrix} =\begin{bmatrix} x_{i_1} \\ x_{i_2} \\ \end{bmatrix} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-a6af803f887a64428b493b3be63f7f71_l3.png?resize=261%2C51)
![\[ $\begin{pmatrix} w_{1_,i} & w_{1_,j} \\ w_{2_,i} & w_{2_,j} \end{pmatrix} \times \begin{bmatrix} i_{i_1} \\ i_{i_2} \\ \end{bmatrix} =\begin{bmatrix} x_{i_1} \\ x_{i_2} \\ \end{bmatrix} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-a6af803f887a64428b493b3be63f7f71_l3.png "Rendered by QuickLaTeX.com")
(3.2) ![\[ o_j= Sigmod(\begin{bmatrix} x_{i_1} \\ x_{i_2} \\ \end{bmatrix}) \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-c6b585a20541e16ddcef8a1e6a01b50d_l3.png?resize=183%2C51)
![\[ o_j= Sigmod(\begin{bmatrix} x_{i_1} \\ x_{i_2} \\ \end{bmatrix}) \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-c6b585a20541e16ddcef8a1e6a01b50d_l3.png "Rendered by QuickLaTeX.com")
(3.3) ![\[ \begin{pmatrix} w_{1_,j} & w_{1_,k} \\ w_{2_,j} & w_{2_,k} \end{pmatrix} \times \begin{bmatrix} o_{j_1} \\ o_{j_2} \\ \end{bmatrix} =\begin{bmatrix} x_{k_1} \\ x_{k_2} \\ \end{bmatrix} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-812de6071dbbefa5f15c9796f7ae158a_l3.png?resize=271%2C51)
![\[ \begin{pmatrix} w_{1_,j} & w_{1_,k} \\ w_{2_,j} & w_{2_,k} \end{pmatrix} \times \begin{bmatrix} o_{j_1} \\ o_{j_2} \\ \end{bmatrix} =\begin{bmatrix} x_{k_1} \\ x_{k_2} \\ \end{bmatrix} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-812de6071dbbefa5f15c9796f7ae158a_l3.png "Rendered by QuickLaTeX.com")
Input орж ирээд эхний layer-т тооцоолол хийгдэж 
 ньюрон дахь өгөгдлийг тооцоолоод гаралт болж
ньюрон дахь өгөгдлийг тооцоолоод гаралт болж  дараагийн layer-т орох бол энэ жишээнд гурав дахь layer output учраас хоёр дахь layer-н гаралт output-н тооцоонд
дараагийн layer-т орох бол энэ жишээнд гурав дахь layer output учраас хоёр дахь layer-н гаралт output-н тооцоонд  орж байна. Мэдээж эдний дунд өөр hidden layer байсан бол адилхан л ийм матрикс үржвэр хийнэ. Харин одоо output-аас error тооцоод тэрийгээ back-propagation хийх тооцоо хийж үзвэл:
орж байна. Мэдээж эдний дунд өөр hidden layer байсан бол адилхан л ийм матрикс үржвэр хийнэ. Харин одоо output-аас error тооцоод тэрийгээ back-propagation хийх тооцоо хийж үзвэл:

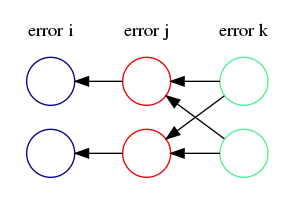
Input/output calculation
error k бол нөгөө target-output гэж тооцож болох бол тэрнээс цааших hidden layer-уудын алдааг яаж бодох вэ? Зурган дээр харагдаж буй адил өгөгдөл хүлээж авч буй ньюрон бүр лүү алдаагаа гаргана гэж үзнэ. Гол нь алдаагаа яаж хуваах вэ гэдэг асуудал. Яахав нийт ньюроны тоонд хувааж тус бүр лүү дамжуулж болох ч ньюрон бүрийн weight харилцан адилгүй. Өндөр weight-тэй ч байж болно үл шалих ч байж болно. Тэгэхээр тэр өгөгдөл дамжуулж буй weight-н хэмжээнд нь тааруулж алдаа дамжуулах нь зүй. Өмнөх layer мх weight-тэй бол их алдаа тэрэн лүү дамжуулна. Энд матрикс үржвэр хийх боломжтой ба өөрсдийнх нь weight-г transpose хийгээд error-уудыг яг өмнөх шиг дамжуулж болох боломжтой болно. Яагаад transpose хийж байгаа юм гэхээр матрикс үржвэрийн хэмжээсийг тааруулах гэж. Ингээд харахаар алдаа дамжуулах томъёо маань:
(3.1) ![\[ $E_j = W_{j_k}^T \times E_k$ \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-444f3316c8d836fbe4a2d3c2d7de797c_l3.png?resize=138%2C27)
![\[ $E_j = W_{j_k}^T \times E_k$ \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-444f3316c8d836fbe4a2d3c2d7de797c_l3.png "Rendered by QuickLaTeX.com")
Өмнөх forward propagation шиг адилхан үржвэр ингээд л өөрийгөө болгосоор байгаад input layer-д оччихно. Тэнд харин input layer-д ямархуу том алдаа бодогдож ирсэн гэдгээ хараад тэндээс хэрхэн сургах вэ гэх тооцоолол эхлэнэ.
Predict, compare, learn
За ньюрон ямартай ч өөрийгөө хэр алдаатай ажиллаж байгааг мэдлээ. Тэр нөхдүүд өөрийн тооцоолсон утга болон ямар байх хэрэгтэй гэдэг утгатай харьцуулж өөрийгөө хэр алдаатай байгааг тогтооно. Үүнийг error function/ loss function гэх нэг функцээр тогтоох ба хэрэглээнээс хамаарч олон янзын байдалтай функцүүд байж болно. Жишээлбэл 
 гэх функц зүгээр хооронд нь хасчиж байгаа бол
гэх функц зүгээр хооронд нь хасчиж байгаа бол  гэх энэ функц модуль аваад хасах алдаа гэж юм байлгахгүй гэж үзэж тарж байгаа бол
гэх энэ функц модуль аваад хасах алдаа гэж юм байлгахгүй гэж үзэж тарж байгаа бол  гэх энэ функц мөн хасах алдаагүй тооцоо хийж байна.
гэх энэ функц мөн хасах алдаагүй тооцоо хийж байна.
Тэгээд тэрийгээ ямар нэг байдлаар засах хэрэгтэй биз тийм ээ. Тэгэхээр юуг өөрчилж ньюрон өөрийгөө сайжруулж болох вэ гэдгийг бодоод үз. Бүх ньюронд өгөгдөл, тооцоо хийх activation function, тооцооны үр дүнг гаргах суваг, бас weight бий. Өгөгдөл болон тооцооны үр дүнг бол бид өөрчилж чадахгүй. Үүнтэй адил сурах гэж байна гээд activation function-аа ч байн байн өөрчилж болохгүй. Activation function өөрчлөх бүр л өөр өөр тооцоо хийгдэнэ. Тэгэхээр бидэнд өөрчилж болох ганц сонголт үлдээд буй нь weight. Ньюрон бүр өөрийнхөө гаргасан алдаанаас хамаарч weight-г өөрчлөх хэрэгтэй гэсэн үг. Гэхдээ яаж?
Хэрэв дунд сургуульдаа тооны хичээлдээ колони тоглож суулгүйгээр хичээлдээ анхаарч байсан бол алдаанаас хамаарч weight-г өөрчлөх гэдэг хэсэг толгойд нь гэрэл цохих шиг мэдрэмж өгсөн байж магад. Ямар нэг зүйлээс хамаарч ямарваа нэг хувьсагчийн утгыг өөрчлөх тооцооллыг уламжлалын ухаанаар (calculus) хийдэг шүү дээ. Нэгэнт уламжлал ашиглах учраас өмнө дурьдсан error function-уудаас хамгийн сүүлийнх нь уламжлал хувьсагчтай тооцоологдож болох учраас хэрэглээнд тохирно. Энд нэг анхаарах зүйл бий нь энэ error function өгөгдөл датаны тэнэмэл утгуудад (outlier, статистакчид энийг монголоор юу гэж нэрлэдгийг мэдэхгүй юм) их том утга бодож гаргана. Арга ч үгүй шүү дээ, бусад датаны өгөгдлөөс хол байгаа утгыг зэрэгт дэвшүүлээд тооцоо хийхээр том тоо гарна. Ийм учраас өгөгдөл датагаа сүлжээнд оруулж сургахаас өмнө сайн цэвэрлэгээ (normalising, feature engineering) хийж өгвөл зүгээр.
За тэгэхээр ньюрон дахь алдааг багасгахын тулд уг алдааг багасгах хэрэг гарна. Өөрөөр хэлбэл уг error function-г minimise хийх хэрэгтэй. Үүнийг gradient descent-н тусламжтай хийнэ. Лаг сүртэй нэртэй энэ эд маань яаж байгаа юм гэхээр өөрийнхөө байгаа түвшинд ямар алдаа байгааг тооцоод, тэрийгээ яаж буулгаж болох тооцоог л хийж байгаа юм. Үүнийг бүх хүмүүс уулнаас бууж байгаа уулчины жишээ ашиглаж тайлбарладаг. Үнэхээр сайн тохирсон жишээ л дээ. Тэрийг энд ашиглавал:
Чи өөрийгөө уулчин гэж төсөөлөөд ямар нэг уулны оройд төөрсөн байна гэж бод. Уулын оройгоос буух төлөвлөгөөтэй байгаа ба тэгж явахын тулд чи эргэн тойрноо хараад аль нь илүү уруу харагдаж байгаа тал руугаа алхаж эхэлнэ. Хамгийн уруу тэр хэсгийг gradient гэдэг. За нэгэнт gradient-ээ олсон бол тэрийгээ дагаж алхаж өөрийгөө тэгж газар очтол буюу ямар нэг уруу явах gradient олохгүй болтол алхана. Тэгж өөрийнхөө уруу гэж бодсон талруу алхаж байгааг gradient descent. Мэдээж энд хэдэн асуудал бий. Нэгд чи өөрийгөө уулын ёроолд очсон байна гэж бодоод нэг довны жалганд оччихож болно. Яг уулынхаа ёроолд очилгүйгээр өөрийнхөө уулын ёроол гэж бодсон газар гацаад үлдэж байгаа байдал шүү дээ. Үүнийг local minima гээд нэрлэчихдэг. Бас үүний хажуугаар хэт том том алхаад уулын ёроол хэсгийг даваад гараад байж болно. Нэг алхаад gradient-ээ бодонгуут хойшоо нэг алх гээд, тэрийг нь дагаад арагшаа алхаад эргээд gradient-ээ бодонгуут бас арагшаа алха гэх байдалд орсон гэсэн үг. Үүнийг gradient тооцож алхалт хийж байхдаа урд нь үржвэр маягаар оруулж өгөх learning rate гэдэг тооны тусламжтайгаар шийдвэрлэж болно. Энэ тоо бага бол ийм байдалд орох нь бага байна. Эсвэл сүлжээ чинь ийм байдалд ороод байвал тэр learning rate-ээ бууруулах хэрэгтэй гэсэн үг.
Ок, error function-г weight-н хамааралтайгаар багасгахын тулд error function-аас weight-ээр уламжлал авч gradient-ээ олоод, тэрийгээ learning rate-ээр үржүүлж weight-ээ өөрчилж алгаадаагаа багасгах нь. Энийг ний нуугүй бичиж байхаар математик гаргалгааг нь харуулсан нь илүү ойлгомжтой харагдана. Тэгэхээр дурын хоёр ньюроны хоорондахь алдааг багасгахын тулд хэрхэн weight-г өөрчлөх томъёоллыг яаж гаргаж байна вэ гэдгийг харуулъя.
Юуны өмнө хэдэн тэнцэтгэл:
(4.1) ![\[ o_{k}=Sigmoid(\sum_{j}W_{j_k}\times o_{j}) \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-3c55cda4373d5457360f7a0e40256243_l3.png?resize=257%2C49)
![\[ o_{k}=Sigmoid(\sum_{j}W_{j_k}\times o_{j}) \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-3c55cda4373d5457360f7a0e40256243_l3.png "Rendered by QuickLaTeX.com")
(4.2) ![\[ E_{j}=t_{n_i} - o_{k} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce8c6def6b2835404a2ad7b998834d0e_l3.png?resize=121%2C20)
![\[ E_{j}=t_{n_i} - o_{k} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce8c6def6b2835404a2ad7b998834d0e_l3.png "Rendered by QuickLaTeX.com")
(4.3) ![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial }{\partial W_{j_k}}\sum_{n}(t_{n}-o_{n})^2 \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-d1b86067e1edc231350f74689980bd50_l3.png?resize=255%2C54)
![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial }{\partial W_{j_k}}\sum_{n}(t_{n}-o_{n})^2 \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-d1b86067e1edc231350f74689980bd50_l3.png "Rendered by QuickLaTeX.com")
(4.4) ![\[ \frac{\partial}{\partial x} Sigmoid(x) = Sigmoid(x)\times (1-Sigmoid(x)) \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-e0f61e63f39638298774dc105ba95779_l3.png?resize=454%2C45)
![\[ \frac{\partial}{\partial x} Sigmoid(x) = Sigmoid(x)\times (1-Sigmoid(x)) \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-e0f61e63f39638298774dc105ba95779_l3.png "Rendered by QuickLaTeX.com")
(4.5) ![\[ W_{j_k}^{new} = W_{j_k}^{old}-\alpha\frac{\partial E}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce0de5fb521700613f4d435bc9e1deb1_l3.png?resize=217%2C50)
![\[ W_{j_k}^{new} = W_{j_k}^{old}-\alpha\frac{\partial E}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce0de5fb521700613f4d435bc9e1deb1_l3.png "Rendered by QuickLaTeX.com")
(4.6) ![\[ \Delta W_{j_k} = W_{j_k} -\alpha\frac{\partial E}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-51b4644235de4f7334ef8113f199df6f_l3.png?resize=208%2C50)
![\[ \Delta W_{j_k} = W_{j_k} -\alpha\frac{\partial E}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-51b4644235de4f7334ef8113f199df6f_l3.png "Rendered by QuickLaTeX.com")
За одоо weight өөрчлөх томъёогоо error function-аас эхлэн хөөж үзэхэд:
(5.1) ![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial E}{\partial o_{k}}\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-aee505a8f3a009b74bc728bd845ae321_l3.png?resize=193%2C50)
![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial E}{\partial o_{k}}\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-aee505a8f3a009b74bc728bd845ae321_l3.png "Rendered by QuickLaTeX.com")
(5.2) ![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial (t_{k}-o_{k})^2}{\partial o_{k}}\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-83c5762fb573f8a5a43cd9ce9e0b0e7a_l3.png?resize=262%2C53)
![\[ \frac{\partial E}{\partial W_{j_k}}=\frac{\partial (t_{k}-o_{k})^2}{\partial o_{k}}\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-83c5762fb573f8a5a43cd9ce9e0b0e7a_l3.png "Rendered by QuickLaTeX.com")
(5.3) ![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-87660f6e46f8b1809ed188d9cce50ed8_l3.png?resize=263%2C51)
![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times \frac{\partial o_{k}}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-87660f6e46f8b1809ed188d9cce50ed8_l3.png "Rendered by QuickLaTeX.com")
(5.4) ![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times \frac{Sigmoid(\sum_{j}W_{j_k}o_{j})}{\partial W_{j_k}} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-57837619c7544e8748b8f9842dc3d58e_l3.png?resize=399%2C54)
![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times \frac{Sigmoid(\sum_{j}W_{j_k}o_{j})}{\partial W_{j_k}} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-57837619c7544e8748b8f9842dc3d58e_l3.png "Rendered by QuickLaTeX.com")
(5.5) ![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))\times \frac{\partial }{\partial W_{j_k}} \sum_{j}W_{j_k}o_{j} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-13243f8eb45adfe4eaf5c13db2715da9_l3.png?resize=782%2C59)
![\[ \frac{\partial E}{\partial W_{j_k}}=-2(t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))\times \frac{\partial }{\partial W_{j_k}} \sum_{j}W_{j_k}o_{j} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-13243f8eb45adfe4eaf5c13db2715da9_l3.png "Rendered by QuickLaTeX.com")
(5.6) ![\[ \frac{\partial E}{\partial W_{j_k}}=-(t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))* o_{j} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-5a58b0f92dedf87f3aa51fa368377de8_l3.png?resize=685%2C59)
![\[ \frac{\partial E}{\partial W_{j_k}}=-(t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))* o_{j} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-5a58b0f92dedf87f3aa51fa368377de8_l3.png "Rendered by QuickLaTeX.com")
(5.7) ![\[ \Delta W_{j_k} = -\alpha * (t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))* o_{j} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-67ab1b616ec7056a48228b8e5619e67c_l3.png?resize=691%2C48)
![\[ \Delta W_{j_k} = -\alpha * (t_{k}-o_{k})\times Sigmoid(\sum_{j}W_{j_k}o_{j})\times (1 - Sigmoid(\sum_{j}W_{j_k}o_{j}))* o_{j} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-67ab1b616ec7056a48228b8e5619e67c_l3.png "Rendered by QuickLaTeX.com")
(5.8) ![\[ \Delta W_{j_k} = -\alpha\times E_k\times o_k\times (1 - o_k) \times o_{j} \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-a33731be3ff184a3f3acbdf19a35116e_l3.png?resize=350%2C22)
![\[ \Delta W_{j_k} = -\alpha\times E_k\times o_k\times (1 - o_k) \times o_{j} \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-a33731be3ff184a3f3acbdf19a35116e_l3.png "Rendered by QuickLaTeX.com")
(5.9) ![\[ \Delta W_{j_k} = -\alpha\times E_k\times o_k\times (1 - o_k)\times o_{j}^T \]](https://i0.wp.com/blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce48933585f8c9709a73a92152f5e2c9_l3.png?resize=355%2C28)
![\[ \Delta W_{j_k} = -\alpha\times E_k\times o_k\times (1 - o_k)\times o_{j}^T \]](http://blog.tumurtogtokh.com/wp-content/ql-cache/quicklatex.com-ce48933585f8c9709a73a92152f5e2c9_l3.png "Rendered by QuickLaTeX.com")
Ингээд гаргаад ирсэн хариу нэг л сонин харагдаж байгаа биз? Томъёонд үлдсэн байгаа өгөгдлүүдийг бүгдийг нь тооцоолоход бэлэн, элдэв ид шидтэй алгоримт ч хэрэггүй. Харин сүүлийн 
 -г transpose
-г transpose  хийж хэмжээсийг нь сольбих шаардлагатай. Яагаад гэхээр W маань
хийж хэмжээсийг нь сольбих шаардлагатай. Яагаад гэхээр W маань  матрикс байх хэрэгтэй, томъёонд байгаа alpha бол тоо,
матрикс байх хэрэгтэй, томъёонд байгаа alpha бол тоо,  бол
бол  вектор байх бол
вектор байх бол  вектор. Энэ хоёр вектор хэмжээс нь өөр учраас үржүүлж болохгүй ба -г transpose хийж хэмжээсийг нь өөрчилж хоёр векторыг үржүүлэхээр өмнөх weight- тэй адилхан хэмжээстэй матрикс болж байгаа юм. Тэр 2-г гээх бол байх зүйл
вектор. Энэ хоёр вектор хэмжээс нь өөр учраас үржүүлж болохгүй ба -г transpose хийж хэмжээсийг нь өөрчилж хоёр векторыг үржүүлэхээр өмнөх weight- тэй адилхан хэмжээстэй матрикс болж байгаа юм. Тэр 2-г гээх бол байх зүйл . Яагаад гэхээр жирийн тоо учир тооцоололд нөлөө үзүүлээд байхгүй. Зарим номонд error function-г эхнээс нь бутархай хэлбэрээр 2-оор хувааж ч эхлүүлдэг. Ялгаа байхгүй. Бас зарим номонд alpha-н урдахь хасах тэмдэгийг хаяаад бичсэн ч байдаг.-д нийлбэрийг яагаад авч хаяж болж байгаа юм гэхээр уламжлал авч байгаа weight-ээс бусад weight нь 0 болох учраас зөвхөн тэр уламжлал авч байгаа ньюронг тооцоонд оруулаад, нийлбэрийн тэмдэгийг хаясан нь нүдэнд ээлтэй байгаа юм л даа xaxa. Түүнээс тэрийг хаяагүй хэдэн давхар нийлбэрийн тэмдэгттэй гаргалгаа бол бас бий бий. Тэрийг бол хүн харахыг хүсэхийн аргагүй.
. Яагаад гэхээр жирийн тоо учир тооцоололд нөлөө үзүүлээд байхгүй. Зарим номонд error function-г эхнээс нь бутархай хэлбэрээр 2-оор хувааж ч эхлүүлдэг. Ялгаа байхгүй. Бас зарим номонд alpha-н урдахь хасах тэмдэгийг хаяаад бичсэн ч байдаг.-д нийлбэрийг яагаад авч хаяж болж байгаа юм гэхээр уламжлал авч байгаа weight-ээс бусад weight нь 0 болох учраас зөвхөн тэр уламжлал авч байгаа ньюронг тооцоонд оруулаад, нийлбэрийн тэмдэгийг хаясан нь нүдэнд ээлтэй байгаа юм л даа xaxa. Түүнээс тэрийг хаяагүй хэдэн давхар нийлбэрийн тэмдэгттэй гаргалгаа бол бас бий бий. Тэрийг бол хүн харахыг хүсэхийн аргагүй.
Кодчилж бичихэд яах билээ?
Одоо ч тэгээд ихэнх хүмүүс Tensorflow, Keras, Pytorch ашиглаж гүний сургалтын систем бичиж байна. Доорх бол Pytorch дээр бичсэн MNIST гараар бичсэн тоо таних систем. 1-3 д системийнхээ input, hidden, output layer-уудын тоог оруулаад яг ньюрон систем үүсгэж байгаа хэсэг бол ердөө 10 мөр код (6-15). Сургалт ажиллуулах ч гэсэн байнга хэрэглэх шаардлагатай функцуудыг цаанаас нь бичсэн болохоор ер нь амар. Forward propagation хийхийн тулд яах вэ? Forward функц. Back propagation хийхэд бас ердөө л backward.
PyTorch-н кодтой харьцуулбал дан python дээр бичсэн бол бүх зүйлийг өөрөө үүсгэх болохоор их явдалтай. Forward propagation хиймээр бол яах уу? Өөрөө бичнэ. Backward ч ялгаагүй. Gradient descent гээд бүгдийг өөрөө бичиж болох ба хэдий их явдалтай ч өөрийнхөө ойлголтыг бататгаж авахад их хэрэгтэй юм даа. Ажиллагааны чадвар бол яахав бусдаас дутах юмгүй. Зөвхөн сурах гэж буй бол өөрөө бичих гэж үзээд, програм бичиж ашиглах бол pytorch, tensorflow, keras гэх мэт framework ашигласан нь дээр. За энэ ч угаасаа ойлгомжтой биз. Сонирхож үзмээр бол энэ gist-ээс хар. Гэснээс энэ python кодны зөвхөн нэг хэсэг нь шүү. Pytorch шиг 10н мөрөнд ньюрон сүлжээ зохиож тансаглах гэх мэт юм байхгүй хаха. За энэ хоёрыг 2ууланг нь jupyter notebook-ээр хийсэн байгааг эндээс харж үзээрэй. Яахав тэгээд оролдоод үзэхгүй юу.
Төгсгөлд
За хамгийн энгийн хиймэл оюун ухаант програм бол нэг иймэрхүү. Ажиллагаа бол энгийн хэдий ч Америкт шуудан холбоонд ийм систем анх нэвтрээд хэдэн сая доллар хэмнэж, хүмүүс олон мянган цагийг зарцуулж захидалд бичсэн байгаа хаягыг төв тооцоолох системд оруулдаг байсан байдлыг өөрчилсөн гэсэн домог бий. Мэдээж хэдэн хүнийг ажлаас халах шаардлагатай байсан биз одоо яаая гэхэв. Капиталист нийгэмд хэн чадвартай нь сайн сайхан явах бичигдээгүй хуультай ч гэх домог бас бий шүү дээ. Харин хэзээ Монголд ийм байдал нүүрлэх бол? Мөнгөгүйгээ гайхдаг орон хэдий ч хаашаа л харна санхүүч, банкир, эдийн засагчид нүдэнд тусдаг хачирхалтай байдал хэзээ алга болох бол доо.
За юутай ч нийтлэлээ хамж дүгнээд чухал санаануудыг базаад тоймлоод бичье.
Хиймэл оюун ухаан ашиглах систем хөгжүүлж болно. Тэгэхээсээ өмнө шийдэх гэж буй асуудлынхаа (domain) талаар сайн тунгаах хэрэгтэй. Энгийн алгоритм ашиглаад тодорхой шийдлийн орон зайд хайлт хийгээд шийдчих боломжтой байна уу? Хэрвээ тийм бол тэрийгээ хөөгөөд явсан нь хурдан амар. Алгоритм ашиглаад шийдэх боломжгүй бол shallow machine learning аргачлалуудаар шийдэж болохоор байна уу? Эдгээр аргачлалууд машин сургалтаас хамаагүй амар, хурдан ба хөгжүүлэхэд их цаг орохооргүй. Нарийвчлалын хувьд 70,80%-тай байх ч хэдхэн секундэд тооцоо хийж үр дүн гаргах чадвартай бол машин сургалт хамгийн сайн компьютерт хэд хоног сургалт хийж байж аппаа ашиглаж болохоор болно. Бас аппаа хэрэглээнд гаргахад ч амар. За үнэхээр тэдгээр арга барилаар оролдмооргүй санагдаад машин сургалтаар хөгжүүлэгдсэн програм бичих бол:
1. Шийдэх гэж буй асуудалд нь алгоритоор шийдэх боломжгүй байх
2. Маш их дата тухайн асуудлыг хүрээнд цуглуулсан байх
3. Тэр асуудлыг шийдэж болох ямар нэг зүй тогтол, шинж чанар датанд олдоно гэдэгт итгэлтэй байх хэрэгтэй.
Бодоод үз, ньюрон сүлжээ чинь зүгээр л ямар нэг зүй тогтол өгөгдөлд олох гэж тооцоо хийнэ. Хамгийн энгийн нэгж нь жирийн шугаман тэгшитгэл байсан шүү дээ. Их дата байх тусам их нарийвчлалтай сүлжээ зохиож чадна. Кодчлол сайн ажигласан бол машин сургалт бол их олон туршилт хийж байх шаардлагатай. Ямар нэг алгоритмлаг аргачлалийн дагуу шийдэл олж байгаа биш болохоор машин сургалт хөгжүүлж буй хүн заавал код бичиж өөрийнхөө системийг туршиж үзэж чаддаг байх хэрэгтэй. Код бичдэггүй бол уучлаарай, чи машин сургалтын систем хөгжүүлж чадахгүй.
Дараагийн нэг чухал зүйл нь машин сургалт их математикт тулгуурлагдсан. Мэдээж мастер, докторын зэргийн математик шаардлагагүй хэдий ч өөрийнхөө туршилтаа үр дүн сайтай хийхийн тулд уг системээ яаж өөрчилбөл яах талаар мэдэхийн тулд зарим талын математикийн ойлголттой байх шаардлагатай. Шугаман алгебр, магадлал, статистик, тэгээд уламжлалын талаар бага сага. Мэдээж эдгээрхийг сурах эх сурвалж бол нетэд бүгд үнэгүй бий. Зарим эх сурвалжыг дурьдвал:
- Deep Learning Book
- Matrix Calculus You need for Deep Learning
- Machine Learning Video Series
- Advanced Introduction to Machine Learning
- Machine Learning for Software Engineers
Яахав одоо олон янзын машин сургалтын хэрэглүүрүүд (framework) гарсан болохоор математикийг яг нарийн түс тас мэддэг байх ч шаардлага бага гарах байх. Одоо бол Tensorflow, PyTorch гэх хоёр том хэрэглүүр бий. Эднийг сурах зарим эх сурвалж:
Энэ нийтлэлд зориулж бичсэн ньюрон сүлжээг дан python дээр бичихээс гадна pytorch дээр ч бичсэн бий. Тэр jupyter-г эндээс харж үз. Хоёулаа чадварын хувьд адилхан ч pytoch дээрх бол их эмх цэгцтэй, нарийн ширийн зүйлсийг заавал өөрөө бичээд байхгүйгээр хүмүүсийн бичсэн функцүүдийг дуудаж ашиглаад л болчихож байгаа биз. Яг нарийн ажиллагааг сурах гэж хиймэл оюун ухааны систем гарааг бичихээс биш бусад үед бол аль нэг хэрэглүүр ашиглаж систем зохионо шүү. Tensorflow, PyTorch хоёроос аль нь сайн бэ гэдэг бол үнэхээр тэнэг асуулт. Ямар ажилд аль нь илүү тохирох вэ гэдэг л юу юм гэхээс биш. Дан хэрэглүүрүүд дээр ажиллаад байж болох ба тэр үед бичиж буй код энэ тэр инженерчлэлийн талаас их харгалзаж үзсэн байх нь зүй. Миний бичсэн тэр код бол зүгээр аль болох хурдан туршиж үзэх загвар боловсруулах зорилготой. Их дататай ажиллах учраас ньюрон системээ үр дүнтэй байлгахын тулд датагаа цэвэрлэх, ижил хэмнэлд оруулах хэрэг бол зайлшгүй.
Хиймэл оюун ухаан, машин сургалтын талаар мэдээлэл авч, энийг сурч буй монголчуудтай ойр байя гэвэл энэ фб групп руу ороорой. Янз бүрийн зар, сүртэй мэдээлэл энэ тэр байхгүй ээ, харин би болон өөр нэгэн машин сургалтын чиглэлээр ажилладаг залуу админ хийж машин сургалтын талаар хэрэгтэй зүйлсийг нийтэлж суудаг юм. Өө тэгээд энийг уншаад ньюрон сүлжээг яаж ажилладаг вэ гэдгийг ойлгоогүй бол эхнээс нь эхлээд мааааааашш удааааанннннаааааааааааар дахин уншаад үзээрэй. УБ Комеди энэ тэр үздэг бол ойлгоогүй байж ч магад. Юмыг яаж мэдэх вэ тийм ээ.
Төгсгөлд энэ нийтлэлд ашигласан ном болон нийтлэлүүдийг доор дурьдсан буй. Яг нийтлэл бичнэ гэж зориод уншиж суугаагүй болохоор ямар хэсгийг хаанаас авсанаа тэмдэглээгүй хэхэ. Яахав ишлэл байхгүй хэдий ч энэ талаар илүү гүнзгийрүүлж унших санаа төрсөн хүмүүс тэдгээр номнуудаас уншиж болно. Бас энэ талаар онлайнаар үнэгүй бие дааж сурах нэмэлт эх сурвалжуудыг сайн сонирхоод үзээрэй. Сонирхсон нэг нь цааш өөрөө судалмой. Гэснээс энэ нийтлэл ямар нэг байдлаар дажгүй санагдвал бусдад тарааж буян болоорой. Түүнээс гадна намайг бас коффеегоор дайлж болно шүү. Аа энд харин ньюрон сүлжээний бүтэн код python-оор, pytorch-оор бий. Нээж үзээд өөрийнхөө компьютерт ажиллуулж үзэхгүй юу. Тэдгээр кодыг яаж л бол яаж болно. Зөвхөн энэ нийтлэлд ашиглах гэж бичсэн учраас ажиллагаанд оруулан програм болгох талаас огт анхаараагүй шүү.
Д.Төмөртогтох
Ашигласан эх сурвалжууд:
Mitchel “Machine Learning”
Ethem Alpaydin “ML The New AI”
Ethem Alpaydin “Introduction to ML”
Stuart Russel and Peter Norvig “Artificial Intelligence: A modern approach”
Stephen Marsland “Machine Learning: An algorithmic perspective”
Cover Image: Photo by Franck V. on Unsplash
![]()